🎯 Цель
Вручную указать диски для сбора метрик SMART для smartd и smartctl_exporter, проверить кеширует ли smartctl_exporter информацию запрошенную от дисков или каждый раз дергает их, настроить параметры опроса задач в Prometheus.
🛠️ Что было сделано
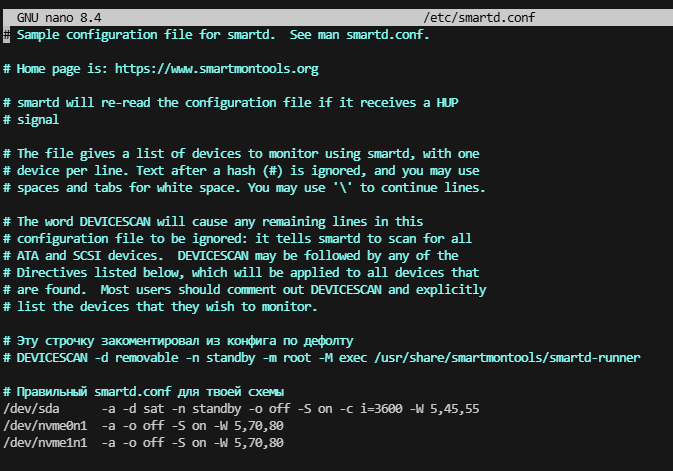
1. Убран DEVICESCAN из smartd
# DEVICESCAN отключён
/dev/sda -a -d sat -n standby -o off -S on -c 3600 -W 5,45,55
/dev/nvme0n1 -a -o off -S on -W 5,70,80
/dev/nvme1n1 -a -o off -S on -W 5,70,80✔ SMART теперь работает строго по указанным устройствам
✔ нет фонового сканирования дисков
2. Smartd переведён в passive режим
- отключены лишние проверки
- включено только базовое SMART-отслеживание
- устранены периодические wakeups
4. Оптимизирован Prometheus
Глобальные настройки:
- scrape interval: 60s
- evaluation interval: выровнен под стабильную работу
- scrape timeout уменьшен до разумного уровня
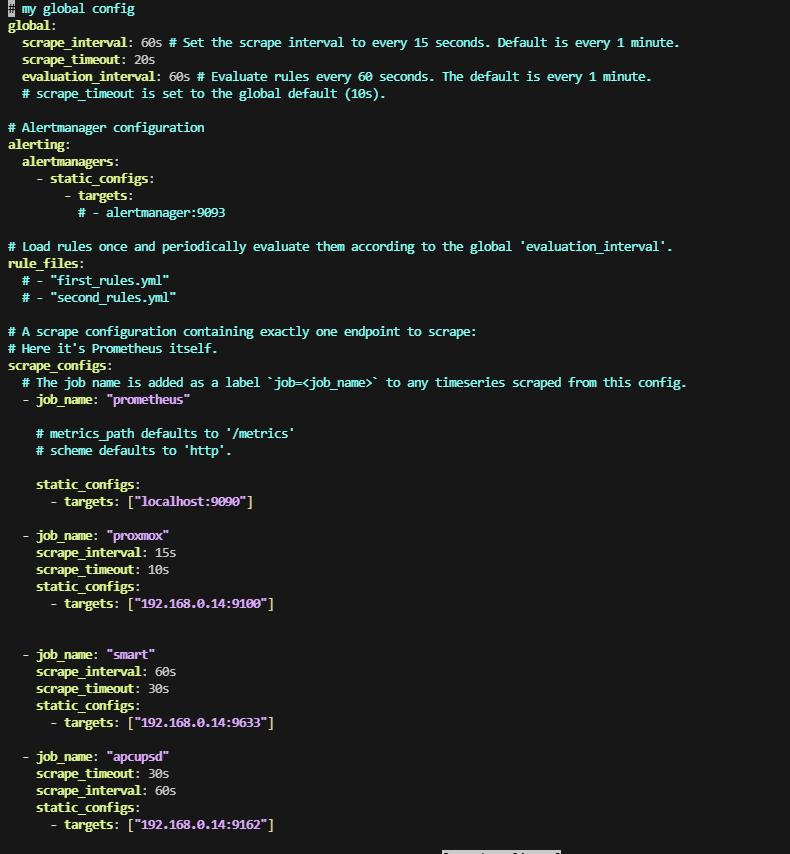
SMART job:
scrape_interval: 60s✔ SMART теперь не участвует в постоянном polling
5. Разделение нагрузки по типам метрик
| Тип | Частота |
|---|---|
| System metrics (CPU/RAM) | 60s |
| UPS | 60s |
| SMART | 60s |
| Disk health | редкий мониторинг |
📉 Результат
✔ Улучшено:
- стабильность latency дисков
- уменьшение IO jitter
- предсказуемость работы storage
- снижение фоновой нагрузки системы
✔ Проверено:
- smartctl_exporter работает в режиме кеширования
🧠 Итоговая архитектура
smartd (passive, per-device)
↓
smartctl_exporter ( SMART polling)
↓
Prometheus (60s system metrics)
↓
HDD / NVMe почти не затрагиваются