Многие привыкли думать: если на графике Grafana «дырка» — значит, сервер падал. На днях я провел расследование аналогичного случая, где сервер не перезагружался, а данные исчезли на 9 часов. Делюсь цепочкой поиска.
Симптомы
График загрузки CPU обрывается в 23:15 и оживает только к 09:00 утра.
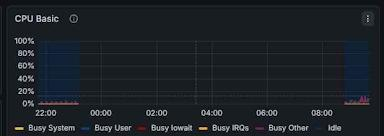
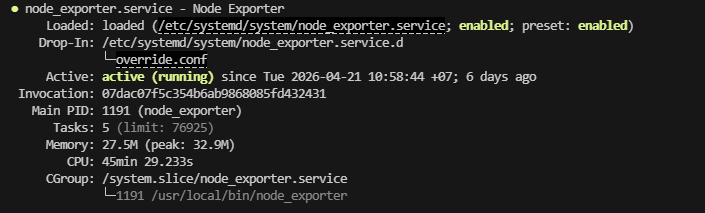
При этом аптайм сервера — 6 дней, а экспортеры работают.

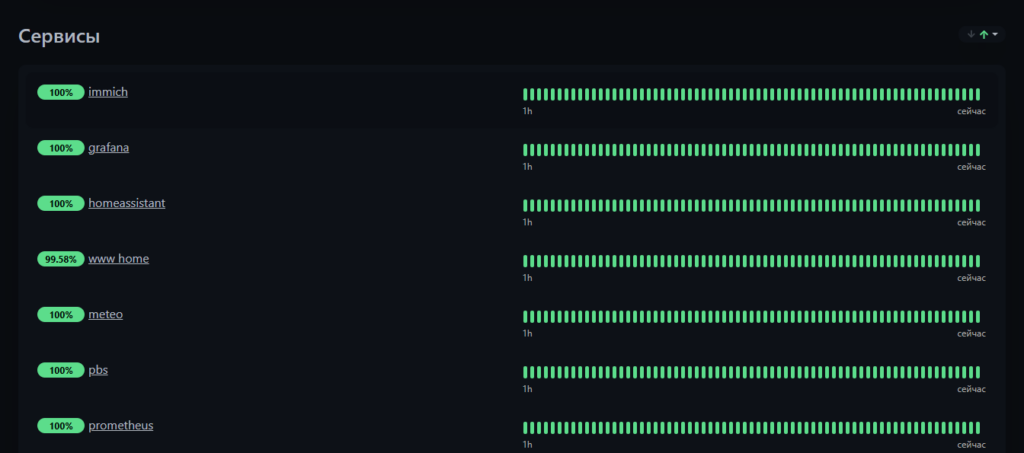
По Uptime Kuma — все сервисы были в работе
Этапы расследования
1. Проверка логов (Broken Pipe)
В логах node_exporter в момент падения посыпались ошибки:error encoding and sending metric family: write tcp ...: write: broken pipe

Это первый звоночек: соединение было разорвано принудительно. Либо сеть, либо принимающая сторона (Prometheus) перестала отвечать.
В логах Prometheus ошибок не было. Штатная работа с базой.

2. Анализ ресурсов (IO Pressure)
Смотрим графики самого гипервизора (Proxmox). Видим страшную картину: IO Pressure Stall подскочил до 40-50% именно в период «дырки». Это значит, что почти половину времени процессы просто стояли и ждали, пока диск освободится.
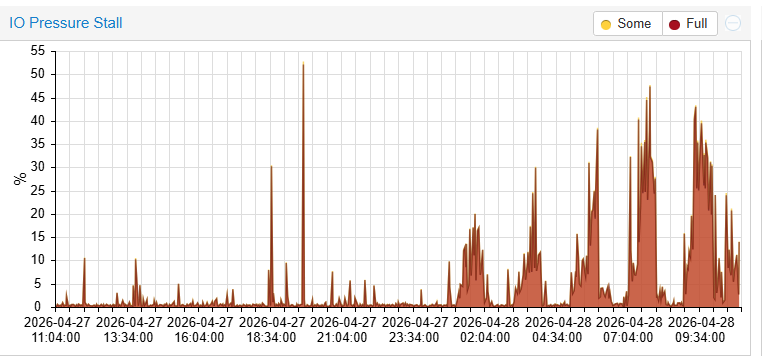
3. Поиск «ночного копателя»
Кто же нагрузил диск? Проверяем расписание:
- 01:00 — 04:00: Бэкапы Proxmox на медленный HDD, но они делаются в другой день


- 02:00: Ежедневный дамп базы данных Postgres.
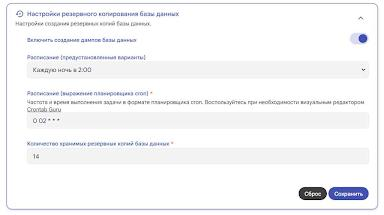
- 00:00: Ночные задачи Immich (распознавание лиц, генерация миниатюр, очистка БД).
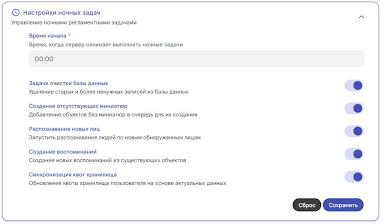
4. Главный подозреваемый — Свободное место
Финальный удар нанес SSD. При детальном осмотре выяснилось, что системный диск (LVM-Thin) заполнен на 91%. Когда на SSD остается меньше 10% места, операции записи становятся мучительно медленными.
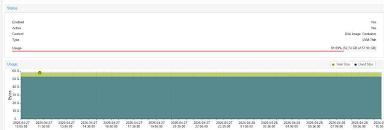
Итог: «Идеальный шторм»
В полночь Immich начал генерировать миниатюры и распознавать лица. Это создало очередь на запись. Сверху наложились бэкапы. SSD, забитый под завязку, не смог быстро выделить место под новые данные. В итоге Prometheus просто не смог записать метрики на диск и «замер», а Grafana показала пустоту.
Как лечить?
✅ Разнести задачи: Ночные регламенты, дампы баз и бэкапы гипервизора не должны идти одновременно.
✅ Дать SSD дышать: Никогда не забивайте системный диск выше 80%. SSD нужен запас для маневров.
✅ Не забывайте про уведомления: Добавьте в Grafana алерт на IO Stall и Disk Space Used, чтобы знать, когда вашим дискам больно
Мораль: Не верьте «дыркам» на графиках — верьте логам дисковой очереди.